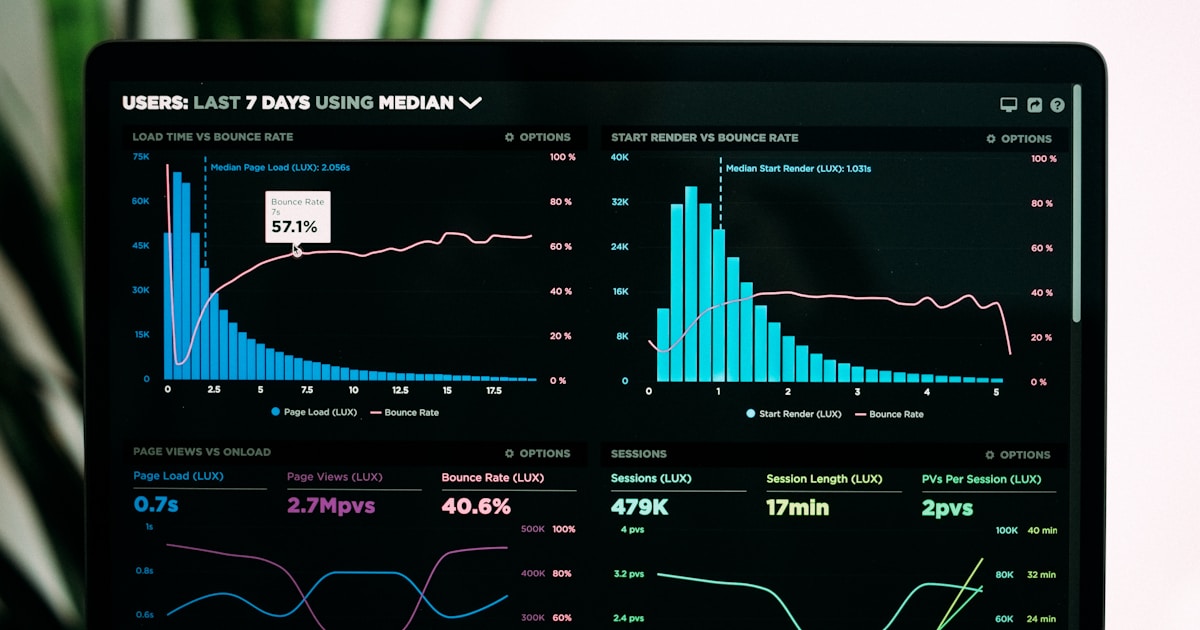
週五下午五點半,老闆的 Slack 出現了:「週報什麼時候好?」
這個訊息,我們公司以前每週固定出現一次。一個人拉 GA4 截圖,一個人整理工單系統,另一個人手動從 GitHub 數 commit 數,最後拼到七點,PDF 傳過去,老闆看了三秒說「謝謝」。整個流程大約耗掉三個人共 4 小時,每週。
這半年,我們公司內部已經跑到 22 條 AI 自動化流程。週報 dashboard 自動生成是最新上線的第 22 條,也是我們這個系列要拆解的第 5 篇 SOP。前幾篇分別處理了報價自動化、排程治理、客服分流與寫稿自動化,這一篇我們要說的是:怎麼把週報整理時數從「人人都在拼」壓縮到只剩 2 個人工審核節點。
本系列已完成篇次:系列第 1 篇:內部報價自動化 SOP / 系列第 2 篇:排程治理 SOP / 系列第 3 篇:客服分流自動化 SOP / 系列第 4 篇:每日寫稿自動化 SOP / 系列第 4 篇:客戶意向與 CRM 同步 SOP。
為什麼老闆的週報永遠是「拼湊到週五晚上」
週報這件事,幾乎每家 10 人到 100 人規模的企業都在做,但幾乎每家都做得很累。原因很結構性:週報需要的數據通常分散在 4 到 8 個來源,沒有一個工具能一鍵拉齊。每個人負責自己熟悉的那一塊,最後再由一個人「整合」,這個整合動作本身就是週五最大的瓶頸。
更大的問題是「數字對不回去」。老闆看到週報說本週網站流量 +12%,但他打開 GA4 自己查,數字差了一截,因為報表用的是「工作階段」,GA4 看的是「使用者」。這種小誤差每週都在發生,最後每個人都對週報失去信任,週報淪為形式。
根據 Gartner 2024 年對中小企業資料治理的調查,超過 67% 的企業主管表示每週花在核對數據的時間超過 2 小時,而這些時間大部分用在確認「數字是否一致」而非分析趨勢本身。自動化週報的核心價值,就是把「核對」這個動作從人工程序變成系統保證。
我們公司踩過的經驗是:週報自動化最大的坑不在 LLM 怎麼寫摘要,而在資料源從一開始就沒對齊指標定義。流量是 session 還是 user?轉換是點擊 CTA 還是送出表單?這些定義沒有在最前面統一,LLM 後面再怎麼摘要都是垃圾進、垃圾出。
問題類型 | 具體症狀 | 發生頻率 |
|---|---|---|
數字來源不一致 | GA4 vs 後台數字差 5-15% | 每週 |
整合時間過長 | 週五下午 3-5 小時人力消耗 | 每週 |
版本控制缺失 | 不知道哪份是最新週報 | 每月 2-3 次 |
摘要不可追溯 | 看不出數字從哪來 | 每季稽核 |
人工錯誤 | 複製貼上錯欄位 | 每月 1-2 次 |
我們公司內部週報 dashboard 的 4 個資料來源
設計任何自動化流程,第一步永遠是把「資料從哪來」說清楚。我們的週報 dashboard 整合了 4 個來源,彼此之間的資料類型、更新頻率、存取方式都不同,這就是為什麼需要一套 SOP 而不是一個 API 串接腳本。
4 個來源分別是:
資料來源 | 提供資訊 | 存取方式 | 更新頻率 |
|---|---|---|---|
GA4(Google Analytics 4) | 網站流量、使用者行為、轉換事件 | GA4 Data API v1 | 即時(T+2hr 延遲) |
Zeabur PostgreSQL | 訂單數、客戶數、服務項目執行狀態 | 直連 PG,SQL 查詢 | 即時 |
N8N 執行日誌 | 各 workflow 執行次數、成功率、錯誤類型 | N8N REST API + webhook | 每次執行更新 |
GitHub Commits | 工程師本週程式碼提交數、PR 合併量、部署次數 | GitHub API v4(GraphQL) | 即時 |
為什麼是這 4 個?因為它們分別對應公司每週最核心的 4 個維度:對外曝光(GA4)、業務數字(PG)、系統健康(N8N 日誌)、工程產出(GitHub)。少了任何一個,老闆看到的週報都是片面的。
技術上,GA4 的資料拉取是最麻煩的,因為 GA4 Data API 有每日配額限制,加上欄位命名邏輯跟 GA Universal 完全不同。我們用一個獨立的 N8N workflow 每週一早上 06:00 UTC 觸發,把上週的資料先快取到 Zeabur PG,後面的摘要流程直接讀 PG,不再重複打 GA4 API。
這個設計原則在我們的排程治理 SOP(系列第 2 篇)裡有完整說明:「每個外部 API 存取都要有本地快取層,不讓 LLM 直接打外部服務」。週報流程完全遵守這條規則。
GA4 Data API 的使用限制與最佳實踐,可以參考 Google 官方文件GA4 Data API 配額管理。我們的快取設計就是為了繞開這個限制,同時確保數字一致性。
LLM 分工設計:Claude Opus 拉數據、Sonnet 摘要、Haiku 排版
我們公司自己每天跑 20+ 個 AI 流程,技術棧是 Claude Code agent + n8n + Zeabur PG + N8N execution log webhook。週報流程的 LLM 分工設計,是基於三個月來踩坑累積出來的原則:用對的模型做對的事,不要讓貴的模型做便宜的事。
具體分工如下:
LLM 模型 | 負責任務 | 為什麼這樣分工 | 平均 token 消耗 |
|---|---|---|---|
Claude Opus | 跨資料源一致性驗證、異常值判斷 | 需要強推理能力,判斷「這個數字合理嗎」 | 約 3,000-5,000 tokens/週 |
Claude Sonnet | 週報摘要撰寫、趨勢分析段落 | 平衡能力與成本,長文摘要主力 | 約 8,000-12,000 tokens/週 |
Claude Haiku | 格式化輸出、表格排版、HTML 生成 | 速度快、成本低,純格式任務 | 約 15,000-20,000 tokens/週 |
這套分工最重要的設計決定是:Opus 只做「判斷」,不做「生成」。我們把 Opus 的任務範圍嚴格限定在「這組數字是否異常」「資料源之間有沒有衝突」,輸出只有 JSON(正常/異常/需確認)。如果讓 Opus 也負責寫摘要,成本會是現在的 3 到 5 倍,但品質提升幅度根本感受不到。
Sonnet 的摘要 prompt 裡有一條硬規則:「每一個數字後面必須帶來源標記,格式為 [source:ga4_cache] 或 [source:pg_orders]」。這個標記在最終輸出時會被 Haiku 的排版 prompt 轉換成 tooltip,讓閱讀週報的人可以 hover 看到數字來源。
更多關於 AI Agent 框架選型的思考,可以參考我們整理的AI Agent 框架選型完整指南,其中關於 task decomposition 的部分跟這個分工設計思路一致。
ℹ️我們做過這件事
恆遠自己每天跑 22 條 AI 自動化流程,技術棧包含 Claude Code Agent、n8n、Zeabur PostgreSQL 和 GitHub Actions。週報 dashboard 這條流程從設計到上線花了 6 週,其中 4 週都在解決資料源對齊問題,LLM 本身只花了 2 週調整。我們目前服務的客製化系統開發案超過 30 件,有興趣了解 AI 系統開發的做法,可以先看 AI 顧問服務 的說明。
3 條品質規則:來源 traceability、數字對得回原始表、沒把握就標「需人工確認」
自動化週報如果沒有品質規則,很快就會變成「沒有人信任但又沒有人停用」的殭屍系統。我們設計了 3 條明確的品質規則,每次生成週報時都會跑一遍檢查,不過才輸出。
品質規則一:來源 traceability
每一個數字都必須能追溯到原始資料表和查詢時間戳。我們在 Zeabur PG 裡建了一張 `report_audit_log` 表,記錄每次週報生成時每個數字的來源 SQL、執行時間、返回值。如果有人事後質疑「上週訂單數是怎麼算的」,直接查這張表,10 秒以內可以重現。
品質規則二:數字對得回原始表
Opus 模型在生成完摘要之後,還要跑一遍「交叉驗證」步驟:把摘要裡出現的每一個關鍵數字,跟原始 PG 查詢結果逐一比對。如果差異超過 0.5%(浮點數四捨五入誤差以外),就標記為異常,進入 human-in-the-loop 節點。這個步驟聽起來繁瑣,但上線後已經抓出 3 次因為時區換算錯誤導致的數字偏差。
品質規則三:沒把握就標「需人工確認」
這條規則的靈感來自我們在客服分流 SOP(系列第 3 篇)設計的「信心分數」機制。LLM 在輸出任何分析段落時,如果信心分數低於 0.75,或者涉及的資料點樣本數小於某個閾值,就在該段落後面加一個 `[需人工確認]` 標記,並附上信心分數和原因。這個機制讓週報閱讀者知道哪些部分是「系統有把握」,哪些部分需要自己再查一下。
這 3 條規則的共同邏輯是:自動化系統要比人工流程更誠實。手工整理週報的時候,人很容易因為時間壓力而「四捨五入」掉不確定性。自動化系統應該反過來,把不確定性明確標示出來,而不是隱藏掉。
關於 AI 系統的 traceability 設計,可以參考 MIT Technology Review 的報導企業 AI 透明度的核心挑戰,其中提到的「解釋性缺口」正是我們設計這 3 條規則想要解決的問題。
2 個 human-in-the-loop 節點:每週三數據冷檢、每週五文字終校

自動化不等於去人化。我們設計了 2 個 human-in-the-loop 節點,把人工介入的時機和範圍明確化,讓參與者知道「我在這個流程裡要做什麼」而不是「我要檢查所有東西」。
節點一:每週三 10:00 數據冷檢(30 分鐘)
週三早上,N8N 會把當週截至週二的數據摘要寄給指定的「數據負責人」(通常是專案經理或資深同事)。這份摘要只有數字,沒有分析文字,格式是標準表格。
負責人要做的事只有一件:確認有沒有「明顯不合理」的數字。不需要解釋為什麼,不需要提出建議,只需要在 Slack 裡回覆「ok」或者標記出可疑的欄位。如果有標記,系統會自動把該欄位的原始查詢 SQL 和資料抽樣發給負責人做二次確認。
這個節點的設計原則是「最小認知負擔」。我們踩過的坑是:一開始要求負責人「確認所有數字並簽名」,結果大家都草草看過沒有真正確認。縮窄到「只找明顯異常」之後,確認品質反而大幅提升。
節點二:每週五 14:00 文字終校(45 分鐘)
週五下午,Sonnet 生成的週報摘要文字會透過 N8N webhook 傳到一個簡單的內部校稿介面(我們用 Notion 頁面加上一個 N8N 觸發按鈕搭出來的)。文字負責人要做的事:讀一遍,確認摘要邏輯通順,修改措辭讓它聽起來像「人寫的」而不是「AI 生成的」。
修改完成後按下確認按鈕,N8N 把最終版本自動發送到老闆的 Slack 頻道、寫進 Notion 週報資料庫、同時存一份 PDF 到 Google Drive。整個流程從週五 14:00 確認到發送完成,通常不超過 5 分鐘。
原本這個流程需要 3 個人共 4 小時,現在壓縮成 2 個人各 30-45 分鐘。節省的不只是時數,更重要的是「週五下午人人焦慮趕週報」這個情緒成本消失了。
如果你想了解更完整的 AI 流程 POC 到落地方法論,可以參考我們寫的中小企業 AI PoC 30 天執行框架,裡面的 human-in-the-loop 設計原則跟本篇一致。
中小企業老闆想跟進怎麼做:4 個技術決策、3 個報價區間
這一段寫給的讀者是:公司有週報需求、對 AI 自動化有興趣、但不確定從哪裡切入的中小企業老闆或營運主管。
4 個技術決策
決策一:資料快取策略。如果你的週報資料來自 3 個以上的外部 API,建議先建一個本地資料庫快取層(Supabase 或 Zeabur PG 都可以),讓所有分析流程讀本地資料,不直接打外部 API。這個決策影響的不只是穩定性,還有成本:重複打 GA4 API 很快就會超配額。
決策二:LLM 任務拆分粒度。建議把「數據驗證」和「摘要生成」拆成兩個獨立 workflow,分別跑、分別紀錄 log。合在一起的 workflow 很難 debug,出問題的時候不知道是哪一步壞掉。
決策三:human-in-the-loop 節點的觸發條件。不要設計成「每次都要人工確認」,要設計成「只有異常才觸發」。具體來說,就是把品質規則寫成明確的數值條件(例如:數字差異超過 2%、某個欄位連續 3 週為 0),只有觸發條件成立時才推送確認請求。
決策四:輸出格式多元化。週報不一定只有一份。建議設計 3 個輸出版本:老闆版(1 頁摘要,重點數字)、主管版(3 頁含趨勢分析)、工程師版(完整原始數據 + 查詢 SQL)。N8N 的條件路由節點可以依照收件人身份自動切換版本。
3 個報價區間
方案規模 | 適合情境 | 主要交付項 | 概抓報價範圍 |
|---|---|---|---|
基礎版 | 2-3 個資料源、單一週報輸出、Slack 發送 | N8N workflow + PG 快取 + 2 個 LLM 節點 | NT$ 80,000 - 120,000 |
標準版 | 4-5 個資料源、多版本輸出(老闆 / 主管)、human-in-the-loop | 完整 SOP + 自訂校稿介面 + 異常監控 | NT$ 180,000 - 280,000 |
進階版 | 多部門週報整合、自訂 dashboard 前端、歷史趨勢比較 | 客製化 dashboard UI + 資料倉儲架構 + 教育訓練 | NT$ 350,000+ |
報價範圍差距大的原因主要在:資料源的整合複雜度、是否需要自訂前端 dashboard、以及 human-in-the-loop 節點的介面開發工時。建議在詢價前先確認「你的週報資料目前存在哪裡、格式是什麼」,這個問題的答案會大幅影響報價方向。
想了解更多關於 N8N 和自動化工具選型的判斷邏輯,可以參考N8N vs Make vs Zapier 完整比較,對剛開始評估自動化工具的老闆很有參考價值。
我們怎麼看:週報自動化真正的槓桿在哪
ℹ️我們怎麼看
週報自動化的真正槓桿在於:讓數字變成可信的溝通語言。當老闆知道週報裡的每個數字都有 traceability,他們就能夠在週報上做真正的決策討論,而不需要先花 10 分鐘質疑數字是否正確。這個轉變對我們公司內部的影響比預期的大很多。週會的前 15 分鐘從「確認數字」變成了「討論下週行動」。如果你的週報也有這個問題,AI 顧問服務 可以協助你設計適合自己公司的系統架構。
如果你的公司目前的週報流程讓你覺得「這件事不應該這麼費力」,那大概率是可以自動化的。歡迎透過AI 顧問服務告訴我們你的狀況,我們會幫你評估資料源整合的複雜度和建議的起步方式。如果有更完整的系統開發需求,也可以直接看客製化網站 & 系統開發的服務說明。
ℹ️我們做過這件事
恆遠數位行銷自己跑 22 條 AI 流程,週報 dashboard 是最新上線的一條。客製化系統開發案超過 30 件,其中 AI 自動化相關專案佔比超過 4 成。我們不把 AI 當賣點,而是自己先用、確認好用再推薦給客戶。想看實際案例,可以到 AI 顧問服務 了解更多。
常見問題
Q我們公司沒有工程師,可以導入週報自動化嗎?
可以,但需要外部夥伴協助初期建置。週報自動化的核心是 N8N workflow 設計和資料庫快取層,建置完成後日常維護不需要工程師。我們設計的系統只需要業務人員做每週 2 次的人工確認,不需要寫程式。建議先跟系統開發夥伴討論你的資料源狀況,再決定方案規模。
QGA4 資料拉取有配額限制,實際使用會碰到問題嗎?
GA4 Data API 的免費配額對大多數中小企業夠用,但如果你的 workflow 設計成「每次生成週報都即時打 GA4 API」就很容易超標。我們的做法是每週一早上一次性把上週資料全部快取到本地資料庫,後續分析都讀快取,GA4 API 呼叫次數壓縮到每週 1 次。
Q週報自動化的導入時程大概多久?
基礎版(2-3 個資料源、Slack 發送)通常 4-6 週可以上線。標準版(含 human-in-the-loop 和多版本輸出)需要 8-12 週,其中資料源整合和指標定義對齊的前置作業通常佔一半時間。進階版含自訂 dashboard 前端的話,建議預留 16 週以上。
QLLM 模型選擇上,一定要用 Claude 嗎?
不一定。我們選用 Claude 系列主要因為它在繁體中文摘要和結構化 JSON 輸出上表現穩定,同時多模型分工(Opus / Sonnet / Haiku)讓成本控制更彈性。如果客戶已有其他 LLM API 合約(例如 OpenAI GPT-4 系列),可以調整 prompt 和 API 呼叫層替換,整體架構設計不依賴特定 LLM 廠商。
Q自動化週報的數字如果出錯,怎麼處理?
我們設計的 3 條品質規則中有一條專門處理這個問題:所有數字都有來源 traceability 記錄在 `report_audit_log` 表。出錯的時候,可以直接查該週的 audit log,看到原始 SQL 查詢和執行時間,確認是資料源問題還是計算邏輯問題,再決定是否要修正歷史週報。
Q這個系統跟一般的 BI 工具(Tableau、Power BI)有什麼差別?
BI 工具的強項是互動式視覺化和 ad-hoc 查詢,但它們本身不生成文字摘要、不整合 LLM、也不處理跨系統資料拉取的快取邏輯。我們設計的週報自動化系統是把 BI 工具的「數據層」加上 LLM 的「摘要層」再加上 N8N 的「流程協調層」三者整合,最終輸出是「可以直接發給老闆看的週報」,而不是要老闆自己去 BI 工具裡點報表。
AUTHOR
恆遠數位編輯團隊
想了解更多?看看我們的相關服務
相關文章

中小企業老闆 AI 寫程式合規稽核完整指南:Cursor / Copilot / Claude Code 4 條法遵紅線、5 個資料外洩情境、3 條稽核模板

中小企業客戶入口網站採購完整指南:Zendesk / Salesforce Experience Cloud / 自架 3 條路徑、6 個決策、5 條合約紅線、90 天上線 SOP

SaaS API 用量爆表 30 天止血完整 SOP:5 個爆表訊號、4 種計費模式踩雷、跟廠商談 credit 的 email 骨架

ESP32 機械手臂視覺辨識夾取完整指南:運算放哪、手臂怎麼選、模型用哪個

手機 NFC 加 ESP32 能做打卡系統嗎?初學者從零動手做完整指南

留言(0)
尚無留言,成為第一個留言的人吧!