

走進中部一家做精密零件的小工廠,產線尾端有一張長桌,桌上擺著一盞日光燈。一位 50 多歲的阿姨戴著放大鏡,一個一個檢查工件——刮痕、毛邊、尺寸不對的退、合格的進。她做了 12 年,眼力是公司的資產,也是公司的瓶頸。她請假那天,全廠不良率立刻往上跳。
這個畫面我們在客製化系統的諮詢現場看過太多次。零售店的店員一邊補貨一邊回想哪個架位該補;農場主每天清晨拿手機拍葉子判斷是不是又有蟲害;保險公司的核賠專員一張一張比對單據真偽。共同點是——人眼能做,但累、慢、不一致,而且請不到人接班。
這類「靠眼睛判斷」的工作,2026 年正在被一件事情默默改變:**圖像訓練**。具體說,是把你公司現場拍到的照片變成一個小到能塞進手機、樹莓派、邊緣盒子的 AI 模型,24 小時幫你看。中間最關鍵的那塊技術叫 **.tflite**(現在的正式名字是 **LiteRT**,2026 年 3 月剛從 Google AI Edge 正式畢業到 production),這篇會把它說清楚。
ℹ️這篇文章寫給誰看
中小企業老闆與廠務、IT、產品經理——你公司現場有「靠眼力判斷」的環節,想搞清楚圖像 AI 怎麼做、要花多少時間和錢、自己土法能不能做、什麼時候該找團隊。技術細節會講到但不會深到要寫 Python,需要寫程式的部分會用 code block 展示,看不懂可以直接跳過。
人眼一天看 8 小時 AI 看一輩子:為什麼 2026 是該動手的時間點
最近半年我們在客製化系統的諮詢案件裡,遇到「想做影像辨識」的詢問次數比前一年翻了一倍多。真正的觸發點是三件具體的事,在 2026 上半年同時發生。
第一件事,技術門檻終於降下來。Google 在 2026 年 3 月把 TensorFlow Lite 正式換名成 LiteRT,並發布到 production——GPU 推論比舊版快 1.4 倍,NPU 加速首次內建,連 PyTorch 跟 JAX 模型都可以直接轉檔不用改架構(MarkTechPost 報告)。這意味著三年前要養一個 ML 工程師團隊才搞得動的事,2026 年一個有經驗的後端工程師加一份顧問報告就能做出 demo。
第二件事,市場規模到了非看不可的程度。Fortune Business Insights 統計,全球邊緣 AI 市場 2026 從 $375 億美金起跳,2034 年要漲到 $3,858 億,年複合成長率 29%(Fortune Business Insights)。電腦視覺是這塊餅最大的應用,製造業、零售、安防是前三大採用產業。Pegatron 跟 NVIDIA 合作用合成資料訓練視覺檢測模型,部署時間縮短 67%——這是 2026 第一季的台灣案例。
第三件事,人不夠用。iFactoryApp 2026 報告指出,AI 視覺檢測線上案例的偵測準確率落在 95-99%、每小時 10,000 件以上,24 小時不眨眼;對照之下人類檢測員在重複性 QC 工作會漏掉 20-30% 的瑕疵,下班後就停機(iFactoryApp 2026)。台灣中小製造業這幾年最頭痛的問題已經從「接不到訂單」轉成「找不到資深 QC」。
技術成熟、市場爆發、人力斷層三件事擠在同一個時間點——我們的判斷是 2026 下半年到 2027 上半年,會是中小製造業跟服務業導入「客製化視覺 AI」的關鍵窗口。先動的人會把人力結構鎖定,慢動的人後面追會比較貴。
圖像訓練到底在做什麼?三種主流任務一次講清楚
技術討論先打底。圖像 AI 看起來是一個東西,實際上拆成三種主流任務,每一種要的資料、模型、難度都不一樣。如果你只記一件事,記這張表。
任務類型 | 在做什麼 | 現場例子 | 標註難度 | 適合的入門模型 |
|---|---|---|---|---|
影像分類 Classification | 判斷整張圖是哪一類 | 這片葉子是健康還是生病、這顆水果是甲級還是乙級 | 低(拉框都不用,整張貼標籤) | MobileNet、EfficientNet |
物件偵測 Object Detection | 找出圖中物件並框出位置 | 貨架上有幾瓶飲料、產線工件有幾個瑕疵點 | 中(每個物件拉一個框 + 類別) | YOLO 系列、SSD |
語意分割 Semantic Segmentation | 把每個像素歸類 | 醫學影像哪塊是腫瘤、衛星圖哪塊是道路 | 高(要塗滿像素級遮罩) | U-Net、DeepLab |
看到這張表先做一個決定:你的問題是哪一種?很多人開頭就跳去研究 YOLO,但其實只要影像分類就能解,徒然把標註成本拉高、模型也養不準。我們在諮詢時最常做的第一件事是把客戶想做的事降階——能用 Classification 解的不要用 Detection,能用 Detection 解的不要碰 Segmentation。階愈低,資料愈少、訓練愈快、上線愈穩。
⚠️降階思維是省錢省時間的第一招
舉例:你想做「不良品偵測」。如果產品在輸送帶上位置固定,鏡頭只要拍一張臉,「合格 / 不合格」二元分類就夠;不需要拉框找瑕疵在哪。後者比前者貴 3-5 倍標註成本、訓練資料也得 5-10 倍。實務上 80% 的工廠 QC 場景,影像分類就能跑出能用的結果。

一份能用的訓練集要花多少時間和錢?標註成本的真實樣貌
圖像訓練 80% 的成本壓在資料標註,這是新手最常低估的部分。把「資料準備好」這件事拆出來看,會發現它比訓練本身難得多。標註行業有一套國際定價,我們先把行情擺出來。
GigaBPO 2026 的價格調查顯示,影像分類標註單價落在 $0.01–$0.15 美金每張,bounding box 物件偵測 $0.03–$0.20 每張,語意分割可以衝到 $0.50–$1.20 每張(GigaBPO 2026 定價基準)。聽起來不貴?來算一筆實帳:要訓練出能上線的物件偵測模型,業界經驗值是每類至少 1,500-3,000 張標註圖片,3 類就是 5,000-10,000 張,光標註預算就是 $1,500-$2,000 美金起跳。Scale AI 級的企業專案,10 萬張醫療影像的標註費用會落在 $15,000-$50,000 美金(GigaBPO 企業預算)。
時間成本更狠。一份來自 Kili Technology 的訪談記錄:freelancer 純手工標註 4,000 張影像花了 55 小時,平均一張 50 秒。對中小企業而言,自己派內勤兼差標 1 萬張圖,等於壓垮一個員工兩個月的產出。
標註方式 | 速度 / 一萬張 | 品質 | 適合誰 |
|---|---|---|---|
純手工內部員工 | 300-500 工時(2-3 個月) | 依工人經驗差異大 | 規模 < 2,000 張、領域很特殊(如自家工件) |
AI 輔助標註(Label Studio / Roboflow) | 60-120 小時(縮短 60%) | 需要人工抽檢 | 規模 2,000-50,000 張、有 IT 能架工具 |
外包標註公司(Scale AI / Surge) | 1-3 週交件 | 高,含 QA 雙重審核 | 規模 > 5 萬張、有預算、要快 |
合成資料 + 真實資料混合 | 看資料生成器,通常 50% 加速 | 依生成器品質 | 瑕疵樣本稀少(如 Pegatron 案) |
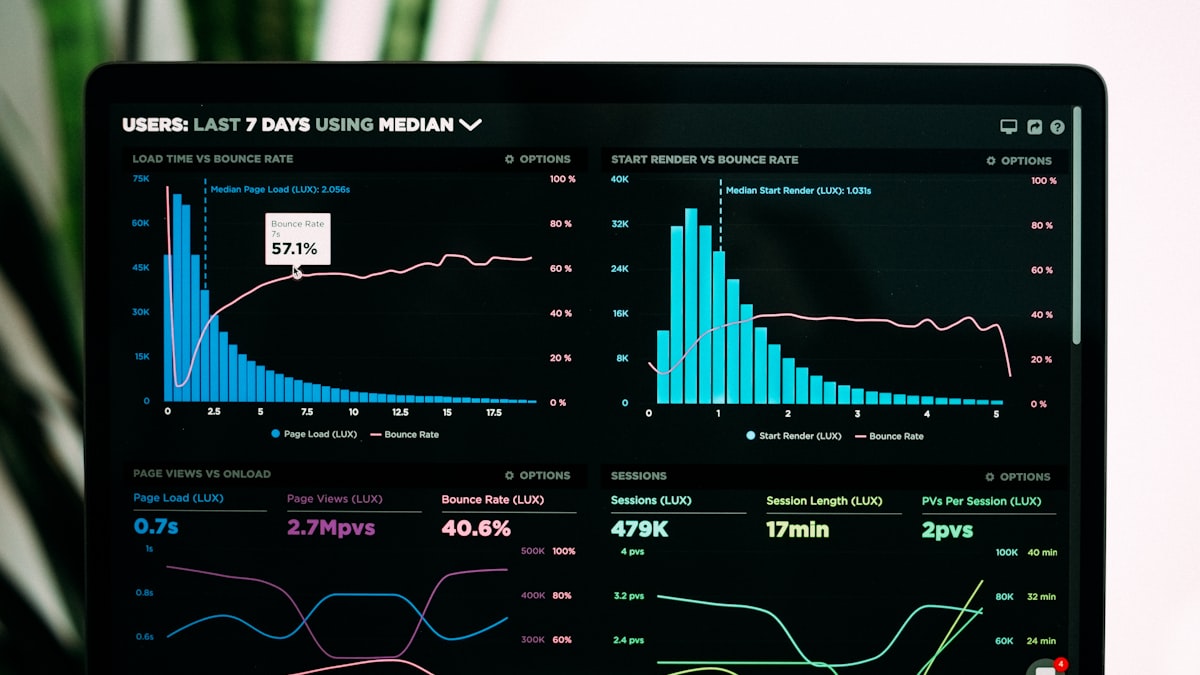
這個階段最常踩的坑有四個。第一,類別不平衡——「合格品」拍了 10,000 張,「不良品」只有 50 張,模型會學到「全部猜合格就好」的偷懶解。第二,標註標準不一致——三個人標同樣的瑕疵,畫的框大小不同,模型訓練起來會抖。第三,邊界案例沒考慮——光線變了、角度變了、產品變色了,模型就壞。第四,沒留評估集——拿訓練的資料去測自己,永遠 99% 準,上線立刻打臉。
模型選型怎麼挑:YOLO、MobileNet、EfficientNet 各擅長什麼
資料標完了,下一步是選一個模型來訓練。2026 的好消息是不用從零開始——主流模型都有 pre-trained weights,你只要用自己的資料做 transfer learning,等於站在 ImageNet 上千萬張圖訓出來的特徵抽取器肩膀上。Ultralytics 的案例顯示,YOLOv8 transfer learning 用 40 張圖就能訓出可用的偵測模型——前提是任務切得夠精準。
模型家族 | 強項 | 弱項 | 推薦場景 |
|---|---|---|---|
YOLO(v8 / v9 / v10) | 物件偵測 SOTA、速度快、生態好 | 分類專案是殺雞用牛刀 | 貨架識別、產線多瑕疵偵測、車牌辨識 |
MobileNet(v2 / v3) | 手機 / 樹莓派友善、模型 2-5MB | 精度不及大模型 3-5% | 邊緣裝置分類、即時辨識 App |
EfficientNet(B0-B7) | 同等運算下精度天花板高 | 推論延遲略長 | 雲端推論、精度優先的醫療類 |
ResNet-50 / 101 | 穩定可靠、CoreML 在這架構推論快 | 模型較大、不適合塞手機 | iOS App、伺服器端 |
ViT(Vision Transformer) | 大資料下精度最強 | 需要大量訓練資料才贏 CNN | 資料 > 10 萬張、研究等級 |
我們的建議很簡單:99% 中小企業專案從 MobileNetV3(分類)或 YOLOv8n(偵測)入門就夠了,輕量、好部署、社群資源最豐富。等基本功跑通、看到 ROI 之後,再去衡量要不要升級到更重的架構。一開始就挑最大最強的,通常是還沒搞清楚問題就先燒錢。
Transfer learning 是中小企業最大的紅利
意思是「拿別人已經訓好的大模型,只重新訓最後幾層用你自家的資料」。資料需求從幾十萬張降到幾千張、訓練時間從幾週降到幾小時、用一張中階 GPU 就能跑。沒有 transfer learning 的年代,做這件事的入場費是 200 萬以上;現在是 20 萬以下。
為什麼一定要懂 .tflite(LiteRT):手機、樹莓派、邊緣盒子的鑰匙
假設你訓出一個模型了,準確率 95%,老闆很滿意。問題來了——它住在你的 Python 環境裡,需要一張 8GB 的 GPU、需要 TensorFlow 完整套件、需要伺服器 24 小時開機。產線現場、店員手機、農場主的手機都跑不了。這就是 .tflite(LiteRT)要解決的問題。
簡單說,.tflite 是把一個訓練好的 TensorFlow / PyTorch / JAX 模型「壓縮 + 重新編譯」成一個檔名 .tflite 的小檔案。原本 100MB 的模型壓成 5MB、原本要 1GB 記憶體跑得起來變成 200MB、原本要 GPU 變成 CPU 就能推論。手機、Raspberry Pi、邊緣盒子(Jetson、Coral USB)都能直接吃這個檔案做 inference。
LiteRT 在 2026 年 3 月隨著 TensorFlow 2.21 一起正式上線 production(Google AI Edge 官方頁)。三件事讓它從一個「行動端工具」變成「企業級基礎建設」——GPU 推論比舊版 TFLite 快 1.4 倍、NPU 加速第一次內建(手機晶片的 AI 加速器終於有官方支援)、PyTorch / JAX 第一級支援不用改模型架構就能轉檔。
我們的判斷:LiteRT 會吃掉行動端 ML 部署 70% 以上的市場——關鍵在於它最穩,跨平台覆蓋度也最完整。AI 開發圈最近常見的爭論是 LiteRT vs ONNX Runtime vs CoreML 三大方案怎麼選——數據結果 Samsung S21 上跑同一個影像分類模型,LiteRT 推論 23ms、ONNX 31ms、PyTorch Mobile 38ms。Android 端 LiteRT 是冠軍,iOS 端 ResNet-50 這類大架構 CoreML 比 LiteRT 快 37%、但 MobileNetV3 LiteRT GPU delegate 反勝 CoreML 47ms。
換句話說:跨平台 App、Android 為主或邊緣裝置 → LiteRT 是預設答案。純 iOS 且模型架構是 ResNet 系列 → CoreML 仍有優勢。需要支援 PyTorch 模型且不想被 Google 綁住 → ONNX Runtime 是後備選項。
一個最小可行的 LiteRT 轉換腳本長什麼樣
讓你有具體畫面——這是把一個訓好的 Keras 模型轉成 .tflite 的完整 Python 腳本。看不懂也沒關係,重點是知道「就這幾行」。
import tensorflow as tf
# 載入訓好的模型
model = tf.keras.models.load_model("my_image_classifier.h5")
# 轉檔器設定:開啟整數量化(模型體積再壓 4 倍、推論快 2-3 倍)
converter = tf.lite.TFLiteConverter.from_keras_model(model)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
# 給代表性資料集(30-100 張就夠),讓量化器知道輸入分布
def representative_dataset():
for img in calibration_images[:100]:
yield [tf.cast(img, tf.float32)[tf.newaxis, ...]]
converter.representative_dataset = representative_dataset
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
converter.inference_input_type = tf.int8
converter.inference_output_type = tf.int8
# 輸出 .tflite 檔案
tflite_model = converter.convert()
with open("my_image_classifier.tflite", "wb") as f:
f.write(tflite_model)
print(f"模型大小:{len(tflite_model) / 1024:.1f} KB")
跑完上面這段腳本,你會拿到一個 2-5MB 的 .tflite 檔案,可以塞到 Android Studio 專案、iOS Xcode 專案、Raspberry Pi 或 Jetson 上做推論。手機端的 Java/Kotlin 程式碼大概 30 行就能呼叫這個模型做即時辨識。

TFLite vs ONNX Runtime vs CoreML:跨平台部署的三條路怎麼選
三大方案的比較表整理如下。實務上 90% 的中小企業專案選擇順序是 LiteRT > ONNX > CoreML,因為跨平台覆蓋度跟生態成熟度差距還是很明顯。
維度 | TFLite / LiteRT | ONNX Runtime | CoreML |
|---|---|---|---|
平台支援 | Android / iOS / Linux / 邊緣裝置全包 | 幾乎全平台、生態最開放 | iOS / macOS only |
模型轉換 | TF / PyTorch / JAX 原生支援 | PyTorch / TF / sklearn 多框架 | 限定 Apple Create ML 或第三方轉檔 |
市佔(行動端) | 約 50%(DZone 2026) | 約 25% | iOS 端約 80% |
推論速度(MobileNet 行動端) | 23ms(最快) | 31ms | 30-38ms(看架構) |
NPU 加速 | 2026 內建 | 需各廠商 EP 各別接 | Neural Engine 原生 |
授權與綁定 | Apache 2.0、Google 主導 | MIT、Linux Foundation | Apple 專有 |
新手難度 | 中(社群資源多) | 中高(文件零散) | 低(iOS 開發者熟悉) |
簡單決策:以 Android 為主或需要跨平台 → 直接選 LiteRT,不用想太多。要把 PyTorch 模型直接搬到行動端、且想避開單一廠商生態 → ONNX Runtime。純 iOS App 且模型架構偏大(ResNet、Inception)→ CoreML。
從訓練到上線的 6 個關卡:每一關都有死人的地方
把整個圖像訓練到上線的旅程拆成 6 個關卡。每一關都有它特定的失敗模式,照這張流程圖走,至少不會走偏。
每一關的常見死法整理在下表。新手最常死的地方往往落在「資料蒐集 SOP 不夠嚴」這一關——拍照角度、光線、距離不一致,模型在實驗室準、上線就崩。模型訓練本身反而沒大家想得那麼難。
關卡 | 常見死法 | 怎麼避免 |
|---|---|---|
1. 問題定義 | 想做 detection 其實 classification 就夠 | 先把任務降階,能用簡單模型解的不要碰複雜的 |
2. 資料蒐集 | 鏡頭角度光線都隨便拍,上線就崩 | 現場架固定燈光與支架,寫拍攝 SOP |
3. 標註與品保 | 三個人標出三種框、沒共識 | 先小批 100 張多人標 + 對齊規則,再放大 |
4. 模型訓練 | 拿全部資料訓練,沒留驗證集 | 70/15/15 切分,validation 是黃金 |
5. 評估與調整 | 只看準確率不看混淆矩陣 | 看每類 precision/recall,找出哪類被誤判最多 |
6. 部署上線 | 量化後精度掉 5%,沒測過直接上 | 量化前後跑代表性資料集對照測試 |
自己土法做還是找團隊做?時間、人力、預算的實算
走到這裡,你應該已經有判斷工具了。問題剩下一個:「我自己組人做」對中小企業划算嗎?我們把實際成本擺出來。
項目 | 自己組人做(DIY) | 找客製化團隊做 |
|---|---|---|
ML 工程師(半年契約) | 月薪 8-15 萬 × 6 個月 = 48-90 萬 | 已含在專案費 |
GPU 開發機 / 雲端訓練 | 本地 RTX 4090 約 6 萬 / 或 AWS 約 5-10 萬/月 | 已含在專案費 |
資料標註人力 | 3-5 萬張內部標 = 2-3 人月 | 外包或團隊內部處理 |
時間到 MVP | 6-12 個月(含試錯) | 8-16 週 |
時間到上線 | 若卡 pilot 則無限延長 | 16-24 週含部署 |
上線維運 | 需要 1 人持續維護 | 可走顧問支援包月 |
典型總成本 | 100-250 萬(含人力試錯) | 30-120 萬(依複雜度) |
失敗風險 | 高(業界 77% AI vision pilot 卡關) | 中(有交付責任) |
「77% AI vision 專案卡在 pilot」這個數字來自 iFactoryApp 2026 的產業統計(AI 視覺 pilot 失敗率)。最常見的失敗原因藏在「組織斷層」——找了一個 ML 工程師,但沒人懂產線、沒人懂部署、沒人懂跟現場師傅溝通,技術本身反而是最沒問題的一塊。一個能跑通的圖像 AI 專案,需要的是「會 ML + 會工程交付 + 會做產品 + 會跟現場走流程」的小團隊,單靠一個天才工程師撐不起來。
中小企業的真實困境是這樣:自己組一個能跑通的小團隊,成本至少 100 萬起跳、時間 6-12 個月,而且第一個專案大概率是學費。對比之下,把第一個案子交給有交付經驗的客製化團隊,反而是把試錯成本壓到最低的方式。等內部跑出第一版能用的模型、ROI 算得出來,再考慮要不要養自己人。
ℹ️我們做過這件事
在我們的 AI 系統開發跟客製化系統開發中,影像辨識整合是常見場景。例如 portfolio 裡的病歷分析管理系統就含 CT 電腦斷層影像處理,我們有處理醫療影像格式、模型整合到既有系統的實作經驗。想討論你公司的圖像 AI 場景能不能落地、預算範圍怎麼抓,可以 跟我們聊聊現況,我們會直接告訴你這個值不值得做、從哪一塊開始最划算。
中小企業老闆該怎麼判斷要不要動手:3 個關鍵自我檢測
我們做諮詢時常被問「我們公司適合做圖像 AI 嗎」。給你三個可以自己回答的檢測,三題答 Yes 就值得認真評估,少於兩題就先放著。
檢測題 | 為什麼問這個 | Yes 的訊號 |
|---|---|---|
公司現場有「靠眼力做重複判斷」的環節嗎? | 圖像 AI 最大價值是取代重複性視覺勞動 | QC、貨架巡檢、文件比對、植物病蟲害、寵物 / 牲畜健康監測 |
這個環節的人力成本 ≥ 一個月 8 萬? | ROI 計算的分母——人力越貴回收越快 | 請了 1.5 人以上專做、或夜班 / 假日加成 |
你有辦法拍到 1,000 張以上的真實場景照片嗎? | 資料是命門,沒資料 AI 就是空談 | 現場已有監視器 / 員工手機隨手能拍 / 過去有照片紀錄 |
三題都 Yes,下一步是花 1-2 小時跟一個有經驗的團隊聊一次,把場景畫出來、把 ROI 試算一下。三題只中一兩題,可能你公司現在還不是動手的時間點——把錢花在數位轉型其他更有立即回報的地方(流程自動化、客服 AI、報價系統)會更划算。
舉一個延伸方向——如果你公司還沒到「視覺辨識」這一步,但有大量重複性文書、客服、報價工作,可以先從 中小企業 AI 自動化 5 個真實場景 或 2026 企業 AI 導入完整指南 起步,跟著流程把容易自動化的環節先吃下來。等內部對 AI 有信心了,視覺辨識會是下一個自然的擴展題。
我們怎麼看:圖像 AI 接下來三年的方向判斷
ℹ️我們怎麼看
圖像 AI 接下來三年會走兩條路:一條是雲端大模型(GPT-4V、Claude Vision、Gemini Vision)吃掉「通用視覺理解」這塊,企業直接呼叫 API 就好;另一條是邊緣端小模型(.tflite / LiteRT / CoreML)吃掉「特定場景、即時、隱私敏感」的工作。台灣中小製造業跟服務業的真實需求 90% 在第二條路上——產線不能等 200ms 雲端回應、客戶照片不能傳到雲端、預算不允許每張圖都付 API 費用。我們的取捨是把客製化資源押在第二條路,因為它跟「站在 AI 巨人肩膀上」這個願景對齊——把模型壓到能跑在手機跟邊緣盒子上、整進企業既有的系統,這才是中小企業真的用得起的 AI。對中小企業老闆而言,現在不用急著買 $1M+ 的 AOI 設備,先想清楚一件事:「我的現場有沒有一個『眼力很貴又找不到人接班』的環節」——有,就值得花 2 小時跟團隊聊聊;沒有,先做別的數位轉型。
AI 導入評估表下載
把這篇講的「3 個自我檢測」「6 個關卡」「DIY vs 客製化成本對照」做成一份 PDF 評估表,可以印出來在公司內部討論。下載連結將在製作完成後補上,先把這篇收藏起來。如果你的需求很急,直接 約一次 AI 顧問諮詢,我們會帶著評估表跟你一起跑一遍。
ℹ️我們做過這件事
順帶說一下,這篇講的方法我們公司自己每天都在跑——目前內部就有 20+ 個 AI 流程在工作中,從寫程式、寫文章到內部知識管理都有 AI 跑在後面。在客製化系統開發裡,我們做過病歷分析管理系統含 CT 電腦斷層影像處理(醫療產業客戶),也做過電商品牌的 AI 智慧客服系統,客服回應時間從 4 小時縮到 3 分鐘、人力成本省 60%。看到這裡,如果你也在想『我們公司現場那個靠眼力判斷的環節,能不能交給 AI』——我們很樂意 聽你聊聊現在的實際情況,一起看看哪些做得起來、能從哪一塊開始。
Q我們公司只有 10 人,做圖像 AI 太早了嗎?
看你現場有沒有「人眼判斷的重複勞動 + 人力成本 ≥ 一個月 8 萬」這兩個條件。10 人公司只要這兩條都成立,圖像 AI 比 100 人公司更划算——人力成本相對營收佔比高、優化空間反而大。真正關鍵的是場景對不對,公司規模反而是次要的。
Q聽說模型要訓練幾萬張圖才會準,這誰受得了?
這是 5 年前的舊觀念了。2026 主流做法叫 transfer learning,拿 Google / Ultralytics 預訓好的模型只重新訓最後幾層,自己的資料 500-3,000 張就能跑出能用的結果。任務切得精準、資料品質好,比資料量大更重要。
Q為什麼非要轉成 .tflite?我用雲端 API 不行嗎?
可以,但有三個情境雲端 API 行不通:第一是即時性(產線 200ms 就要結果,雲端來回 800ms),第二是隱私(醫療、財務影像不能傳上雲),第三是成本(每張圖呼叫一次 API,1,000 張 / 天就破萬元 / 月)。.tflite 把模型放本地,這三個問題一起解。
Q我們是 iOS App,應該選 LiteRT 還是 CoreML?
如果你的模型架構是 ResNet 或 Inception 這類大 CNN,CoreML 在 iOS 上推論比 LiteRT 快 30% 左右。但如果是 MobileNetV3 之類的輕量模型、或者你需要同時支援 Android,直接用 LiteRT 比較省事——一份模型跨兩個平台。建議先用 LiteRT 跑 MVP,瓶頸出現再考慮為 iOS 單獨優化成 CoreML。
Q標註資料一定要找專業公司嗎?我們員工自己標可以嗎?
資料量 < 2,000 張、且資料是公司專有領域(如自家工件外觀、自家產品型號),員工自己標反而精準。資料量 > 5,000 張、或標註規則複雜(含像素級分割),找專業外包比較划算。中間地帶 2,000-5,000 張,建議用 Roboflow / Label Studio 這類 AI 輔助工具,內部 1-2 人花 1-2 個月解決。
Q做完一版模型,現場發現新的瑕疵類型,要全部重來嗎?
不用,但要看新類型有多新。如果是同類瑕疵的變體,加 100-300 張新資料微調(fine-tune)就好,幾小時搞定。如果是完全新的類別(例如原本只測刮痕、現在多了凹陷),需要把新類別加進訓練集、重訓最後幾層,1-2 天可以搞定。模型上線後資料持續回流是正確設計,不是失敗。
結語:圖像 AI 已經是中小企業也用得起的新工具
三年前說圖像 AI,我們會建議大部分中小企業先觀望。2026 不一樣了——LiteRT production 上線、transfer learning 把資料門檻降到幾百張、邊緣裝置便宜到 3,000 元一台、開源模型品質追上商業方案。技術門檻第一次低到中小企業可以動手。
唯一的問題是「要動手做什麼」。這篇給你了三個自我檢測、六個流程關卡、三大部署方案的比較。下一步是把這套框架套到你自己公司的現場——哪個環節最痛、哪個值得先試、預算抓多少。
如果你想跳過自己摸索的階段,直接跟有經驗的團隊聊一次,可以 約一次 AI 顧問諮詢。我們會帶著這篇的框架跟你的現場資料,跑一遍評估,告訴你「這個值得做嗎、大概要多少預算、怎麼分階段做最划算」——這個階段我們陪你一起想,後面真的要動手再談範圍跟費用。也可以從 AI 系統開發服務頁 看我們在這塊的服務範圍,或從 客製化系統開發 看我們做過的整合案例。
AUTHOR
自由揚John
想了解更多?看看我們的相關服務
相關文章

業務 pipeline 5 階段設計實戰:中小企業 CRM 從 lead 到成交的落地 SOP

中小企業 LINE 官方帳號接 AI 完整實戰指南:3 種整合路徑、5 條資料紅線、4 種計費模式踩雷

中小企業 LLM API 帳單 FinOps 完整治理指南:6 個帳單訊號、5 條成本紅線、4 種預算控制模式、3 種團隊規模預算試算

中小企業老闆 AI 寫程式合規稽核完整指南:Cursor / Copilot / Claude Code 4 條法遵紅線、5 個資料外洩情境、3 條稽核模板

企業機密資料 secrets 管理採購完整指南:HashiCorp Vault / AWS Secrets Manager / Doppler / 自架 4 條路徑、5 個決策節點、3 種團隊規模預算
留言(0)
尚無留言,成為第一個留言的人吧!