

我們經營這個部落格的時候,記憶體曲線差點把伺服器送進 ICU。重啟之後 30 秒內,process 的 RSS 從 80MB 一路爬到 780MB,然後就在那邊像心電圖平緩線一樣 plateau,怎麼等都不下來。前一天還是好好的 Next.js 服務,怎麼一個排程腳本就把整個容器吃成胖子?
這是一篇真實的事故復盤。我們踩過兩個誤解、拆過一個 request 的 V8 heap 軌跡、最後挑了一個跟 V8 完全不對著幹的解法。如果你也在自架 Next.js、Express、Payload、NestJS 這類長跑(long-running)Node.js 服務,看到記憶體只升不降,這篇文章會把整條因果鏈、4 個級別的解法、以及我們最後為什麼選了一條看起來最偷懶其實最乾淨的路,全部講清楚。
先給結論:V8 heap 不會把 RAM 還給作業系統,這其實是刻意的設計,並非 bug。 你越是想用 GC 強迫它縮小,越會掉進 anti-pattern;正解是把長跑工作量從 process 內部移走,讓 process 維持低水位。這也是 Vercel、AWS Lambda、Cloudflare Workers、Kubernetes Pod maxAge 整套主流架構共同的哲學。看完這篇文章,你會知道為什麼。
第一個誤解:ISR 1 小時過期,記憶體應該會降吧?
事故發生那天的監控曲線長這樣——重啟後幾秒內 RSS 飆升,5 分鐘內衝到 780MB,然後就靜止在那。我盯著 Grafana 看了 40 分鐘,心想:「不對啊,我們設了 ISR revalidate = 3600,等到 1 小時後快取過期,記憶體總該降下來吧?」
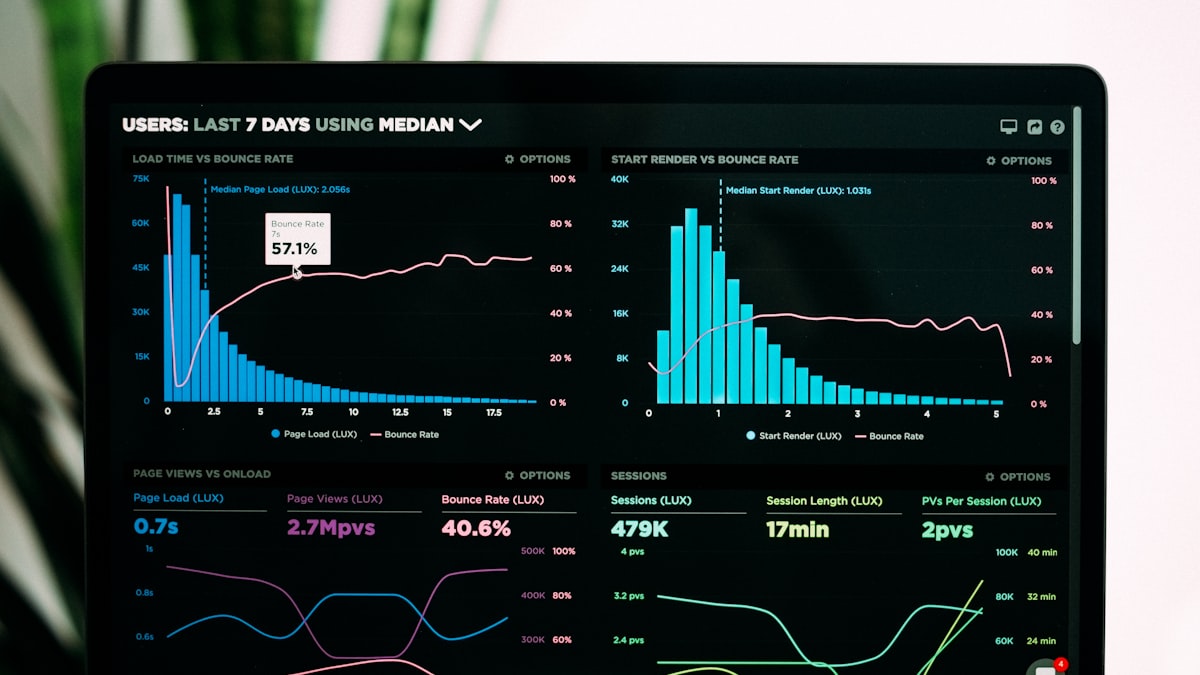
一個小時後——維持 780MB,沒動。兩個小時後——還是 780MB。重啟一次再跑 warmup,又一次衝到 780MB plateau。整個服務看起來健康,response time 沒慢、500 沒變多,但記憶體就是不還給 OS。這時候才意識到,我把兩個完全不同層次的快取搞混了。
Next.js 的 ISR(Incremental Static Regeneration)寫的是 filesystem cache。當你打開 .next/cache/fetch-cache/ 目錄,會看到一堆 hash 檔名的 JSON 檔,那才是 ISR 的本體。revalidate 1 小時到期,動到的是這些硬碟上的檔案——下一個 request 進來時,Next.js 重新跑 generateStaticParams 的 fetch、把結果寫回硬碟。整個過程跟 V8 heap 一點關係都沒有。
我們事故當時的腳本邏輯是這樣:scripts/warm-cache.sh 在 startup 階段被呼叫,內部用一個 for 迴圈打 ~300 篇文章的 URL,目的是預熱 ISR 快取。每一個 request 觸發 SSR render,把 Lexical JSON 轉成 React element tree、再 renderToString 成 HTML 字串。這些中介資料統統會被 V8 配在 heap 裡,warmup 結束後雖然這些 reference 都被釋放、GC 也跑了,但 process 的 RSS(Resident Set Size,常駐物理記憶體)永遠不縮。
觀察維度 | V8 heap(RAM 內) | ISR / Next.js cache(硬碟內) |
|---|---|---|
儲存介質 | Process RSS(OS 配給的物理記憶體) | .next/cache/* 的 JSON / HTML 檔案 |
過期機制 | 不過期,跟著 process 生命週期 | revalidate 秒數到期後重新生成 |
釋放動作 | GC 標記為可回收,但 RAM 不還 OS | 檔案會被覆寫或刪除 |
受重啟影響 | 整個 heap 歸零 | 檔案還在,下次重啟仍可命中 |
能用 ISR 設定影響? | 不能,跟 ISR 完全無關 | 能,revalidate / cacheTags 直接控制 |
這張表是我事故當天才搞清楚的。在那之前,我下意識把「快取」當成一個整體——設了 1 小時過期應該就會釋放——其實 Node.js 的世界裡,「快取」最少分四層:CDN edge cache、瀏覽器 cache、Next.js fetch cache、V8 heap object。前三層可以用過期時間管理,第四層完全是 V8 自己的事,你管不到。
⚠️別被「過期」這個詞騙了
ISR、Redis、Memcached 的「過期」都是邏輯層面的標記,跟 V8 heap 的物理釋放是兩件事。RAM 由 V8 與作業系統的記憶體配置器(malloc/free)管理,跟你應用層設的 TTL 無關。看到記憶體只升不降,第一時間應該打開 process inspector,不是去調 ISR 設定。
第二個誤解:GC 跑了,記憶體應該被回收?
第一個誤解破解後,我立刻試了第二個直覺解:強制觸發 GC。Node.js 啟動時加上 --expose-gc flag,然後在 warmup 結束的 callback 裡呼叫 global.gc(true),跑 full GC。理論上 GC 跑完,所有不可達的物件都被掃掉,記憶體應該降才對。
結果——RSS 還是 780MB,沒動。但同時間用 v8.getHeapStatistics() 看 heap 內部,used_heap_size 確實從 700MB 降到 60MB。這就是事故給我上的最重要一課:V8 heap 內部的「使用中」與 process 對 OS 的「持有量」是兩條不同的曲線。
V8 的 heap 是一個由 V8 自己管理的大池子。當 V8 啟動時,它不會直接讓你的物件躺在 OS RAM 裡,而是先跟 OS 要一塊大空間(透過 mmap 或 brk),然後在這塊空間內部自己當地主,分配給每一個 JS object。GC 做的事情是「在這塊地裡標記哪些房間可以重新出租」,但整塊地皮不會還給 OS,因為 V8 預期之後還會有人來租。

GC 階段 | 負責區域 | 觸發時機 | 是否會把 RAM 還給 OS |
|---|---|---|---|
Scavenge(Minor GC) | New space(年輕代) | New space 滿(~16MB) | 不會 |
Mark-Sweep / Mark-Compact(Major GC) | Old space(老年代) | Old space 達到 GC threshold | 極少數狀況可能 madvise,但 RSS 通常不變 |
Idle GC | New + Old space | Event loop 閒置時 | 不會 |
global.gc(true) 強制 Full GC | New + Old space | 手動呼叫 | 理論上會 try shrink,實際幾乎不縮 |
V8 把 heap 分成 New Generation 跟 Old Generation 是有原因的。Crankshaft 早年的研究發現大部分 JS object 都活不過第一次 GC(叫做 weak generational hypothesis),所以 V8 把新物件先放在小小的 New space 跑高頻 Scavenge,活下來的才會晉升到 Old space 跑成本較高的 Mark-Sweep。問題是 warmup 階段製造的物件量大、活太久、又集中爆發,這些物件會被全部晉升到 Old space,把 Old space 撐到 800MB 量級。等到 warmup 結束你終於能 GC,Old space 空了,但 V8 的策略是「保留」這塊已經要到的地皮,因為「下次說不定還會用到」。
這在 V8 設計師的想法裡是對的——重複跟 OS 要記憶體(malloc / mmap syscall)非常昂貴,而且容易製造 fragmentation。預先保留高水位是 V8 的攻擊性配置(aggressive allocation) 策略。從 V8 的角度看這是優化;從你的監控角度看,這就是「記憶體爛尾樓」。
用一個 request 拆解 V8 heap 在做什麼
為了把 V8 的行為講清楚,我把事故當天追蹤過的一個 request 完整時間軸畫出來。當你打 /blog/some-slug 這個 URL,從 request 進來到 response 送出,V8 heap 內部到底在發生什麼——這條軌跡就是 warmup 撐爆 heap 的根本原因。
看到 T=25ms 那一段了嗎?Lexical JSON 轉換成 React element tree 的瞬間,heap 暴漲 1-2MB。一篇中等長度的部落格文章 jsonb 在 PG 裡大約 60KB,parse 完變成 200KB 的 JS object(因為 V8 的 hidden class、property descriptor、字串去重前的暫存等等)。Lexical 再把這 200KB 轉成 React 的 element tree,一個 type: paragraph 節點會展開成多個 React element + props object,這一展就是 5-10 倍的記憶體膨脹。
假設一個 request 在 heap 上製造 2MB 物件,warmup 連發 300 篇文章——每篇分別在不同 Promise.then 鏈裡駐留——理論最壞情況 600MB 同時活著(如果 GC 來不及清)。實務上 V8 會在 New space 滿時頻繁 scavenge,但晉升到 Old space 的物件夠多,最終 Old space 撐到 700-800MB。這就是事故的根源:warmup 真正的問題是用力過猛,跟「慢」沒關係。
ℹ️為什麼 Lexical 轉換特別吃記憶體
Lexical 為了支援 collaborative editing 跟 undo / redo,每個 node 都會包一層 metadata(version、direction、format、textStyle 等),單一 paragraph 的 JS 物件大小通常是純文字的 4-6 倍。轉成 React element 時還會多出 props、key、ref 等欄位。這在 client 用幾乎沒感覺,但 SSR 連發幾百篇就會變成 RAM 災難。
V8 為什麼不把記憶體還給作業系統?
這個問題我問了三個工程師朋友,得到三種不同答案:「設計缺陷」「performance 優化」「都是」。從 V8 source code 跟官方 design doc 的角度看,正確答案是第三個。V8 不還 RAM 是有意為之的,背後有三個工程理由。
理由一:syscall 成本太高
每次跟 OS 要記憶體(malloc / mmap)或還給 OS(free / munmap)都是 syscall。Linux 上一次 mmap 大概 1-3 微秒,看起來不多,但 GC 在熱點路徑上跑——一次 Mark-Sweep 可能要動到上萬個物件,如果每個釋放都做 munmap,整體 GC pause 會拉到不能接受的程度。V8 的策略是:跟 OS 一次要一大塊(page chunk),自己內部當二房東,內部劃分用 free list 管理。這樣只有「擴張」跟「初始保留」需要 syscall,日常釋放完全在 user space。
理由二:避免 fragmentation
如果 V8 真的把每一塊 GC 過的記憶體都還給 OS,下次需要分配時又要重新跟 OS 要——但 OS 給回來的位址不一定是連續的。這對 V8 的 generational GC 是災難,因為 New space 跟 Old space 都需要連續的位址範圍才能跑 bump pointer 配置(最快的分配策略)。一旦碎片化,V8 必須改用較慢的 free list lookup,整體配置速度會掉一個量級。 保留高水位等於保留連續位址,是純粹的 performance 考量。
理由三:負載預測模型
V8 內部有一個叫 HeapGrowingFactor 的算法,預設是 1.5-2x:每次 Old space 撐到上限時,V8 會 grow 到目前 size 的 1.5-2 倍。這是因為 V8 假設「會撐到這麼大表示工作負載確實需要這麼多」,與其等下次 GC 又馬上不夠用,不如一次給足。問題是 grow 容易、shrink 難——一旦衝高,V8 沒有對稱的縮減策略。Node.js 22 之後有實驗性的 --max-semi-space-size-growth-rate 但只影響 New space,Old space 高水位的問題依然存在。
這三個理由綁在一起就是業界共識:不要跟 V8 鬥智,把長跑工作量移走才是正解。Vercel 把每個 request 跑在獨立的 serverless function(cold start 後 process 死掉、heap 歸零),AWS Lambda 強制 15 分鐘 max execution、idle 一段時間就 freeze process,Cloudflare Workers 直接用 isolate-per-request 的 V8 沙盒,本質上都是同一招——讓 process 短命,就不會有高水位累積。

解法 4 級制:從髒到乾淨
把所有可行解法依「對抗 V8 程度」由高到低排,會得到這張決策樹。我們事故當下逐一試過級別 1、2、3,最後落在級別 4,並且選了 4c 這個變體。先看圖再講細節。
級別 1:限制 max-old-space-size
最直覺的做法:在 NODE_OPTIONS 設 --max-old-space-size=600,等於告訴 V8「Old space 最多 600MB,超過直接 throw」。看起來解決問題,實際上把問題從「記憶體偷偷漲」換成「記憶體一漲就 crash」。warmup 高峰如果撞上 600MB 上限,process 直接 OOM exit,整個服務暴斃。這個級別只適合你能保證 peak workload 永遠低於上限的情境,不適合 warmup 場景。
🚨max-old-space-size 是雙面刃
設太低 = 直接 OOM crash;設太高 = 跟沒設一樣。實務上要做壓力測試確認 peak heap 在哪、再加 30% buffer。Container 環境特別容易踩坑——容器只給 1GB RAM、你卻設 max-old-space-size=2048,V8 以為自己有 2GB 可用,結果 OS 會在到達 1GB 時直接 OOM kill 整個容器,比 V8 自己 throw 更慘烈。
級別 2:手動觸發 GC(anti-pattern)
啟動時加 --expose-gc flag,在 warmup 結束的 callback 裡呼叫 global.gc(true)。實測有效——heap 內部的 used 確實會降——但 RSS 不一定降,而且這個寫法在 Node.js 社群被普遍視為 anti-pattern。原因有三:
- GC 是 V8 的內部決策,應用層直接呼叫等於繞過 V8 的最佳化判斷,可能害你錯過真正該跑 GC 的時機;
- global.gc 是 stop-the-world,跑大 heap 的 full GC 可能 pause 100-300ms,這段時間整個 event loop 被凍住,所有進行中的 request 全部延遲;
- production 環境如果忘了加 --expose-gc,global.gc 會是 undefined,呼叫直接 crash;加了 flag 又會被靜態分析工具標 warning。
級別 3:定期重啟
不去動 V8、不對抗高水位,改成「每隔幾小時或記憶體達到閾值時重啟 process」。PM2 有 max_memory_restart: '700M' 的設定、Zeabur 跟 Railway 都支援 schedule-based restart、k8s 用 livenessProbe + 記憶體 limit 達到就 restart pod。這個方法務實但有兩個前提:
- 你的服務必須是 stateless(重啟不會掉資料、不會中斷正在進行的長 request);
- 重啟過程要做 graceful shutdown,等現有 request 跑完再 kill,否則 5xx 會飆。
級別 4:把 workload 移出 process
最乾淨的做法:問「這個讓 heap 撐高的工作,真的要跟 web server 跑同一個 process 嗎?」對 warmup 而言答案是「不必」。這條路有三種變體:
- 4a:外部 cron container — 起一個獨立的 sidecar 或 worker container,專職跑 warmup 腳本。執行完整個 process exit,記憶體歸零。
- 4b:GitHub Actions — 把 warmup 腳本放到 GitHub Actions schedule cron,每天凌晨跑一次預熱。完全不消耗你的 production 資源。
- 4c:邊緣快取永久化 — 用 Cloudflare Cache Reserve、Vercel Edge Cache、Fastly 等 CDN 永久存放 HTML,連 warmup 都不需要。Google bot、使用者第一次訪問也是命中 edge。
解法級別 | 實作成本 | 風險 | 效果 | 適合誰 |
|---|---|---|---|---|
L1:max-old-space-size | 低(一行 env) | 高(spike 即 crash) | 有上限但會炸 | 已知 peak 低於上限的服務 |
L2:手動 global.gc | 低 | 中(anti-pattern + pause) | heap 內降但 RSS 未必 | debugging / 不建議 prod |
L3:定期重啟 | 中(要 graceful shutdown) | 低(已成熟做法) | 根治高水位問題 | 中小團隊、stateless 服務 |
L4a:外部 cron container | 中(多一個服務維運) | 低 | 根治 | 有 k8s / sidecar 能力的團隊 |
L4b:GitHub Actions | 低(YAML 設定) | 低 | 根治 | 已用 GitHub 做 CI/CD 的團隊 |
L4c:CF Cache Reserve | 低(一個 toggle) | 低 | 根治 + 邊緣命中 | 用 Cloudflare 做 CDN 的服務 |
我們最後的選擇:為什麼決定砍掉 warmup
最後我們選了 4c:開啟 Cloudflare Cache Reserve、設定 /blog/* 整路徑 Cache-Control: public, max-age=86400, s-maxage=86400, stale-while-revalidate=604800,並把 scripts/warm-cache.sh 從 startup hook 移除。整個改動 30 分鐘做完,部署後當天記憶體曲線就乾淨了——重啟後 RSS 維持 80-120MB 之間,再也不會看到那道從 100 衝到 800 的爛尾。
這個決定的關鍵在於經濟學,技術反而是其次。我把四個方案的隱藏成本攤出來看:
- L1(限上限):成本 0,但每次 warmup 都在賭命,運維壓力大。
- L3(定期重啟):成本 0,但每天要安排凌晨低流量時段重啟,對 SLA 99.9% 服務有破口。
- L4a(cron container):要多開一個 container,Zeabur 帳單多 100-200 元/月,還要維護 container image。
- L4c(CF Cache Reserve):CF Cache Reserve 計費約 $0.20/月(我們流量級距),warmup 完全砍掉,process 永遠低水位,Google bot 也是吃 edge cache 不打到 origin。
為什麼業界主流走 4c 路線
Vercel、Netlify、Cloudflare Pages 出廠就預設 edge cache,本質上就是把每個 page 永久放在 200+ 個邊緣節點。你不需要 warmup,因為 cache 已經比你的 origin 還近、還久。自架 Next.js 想要相同效果,最快的辦法就是把 CDN 的 cache 拉長到「等於頁面實際變動週期」——部落格文章一週改一次?那 cache 就放一週,配合 stale-while-revalidate 跟 on-demand revalidate API,永遠零 origin 壓力。
對比之下,L4c 把所有問題一次解決:V8 heap 不再被 warmup 撐高、Google bot 第一個 request 也是吃 edge、origin 只在內容更新時被打到。這就是工程上常說的「換層思考」——當你在某一層怎麼解都很醜時,往上一層通常一個 toggle 就解決。ISR + Cache Reserve 之於 V8 heap 高水位,就是一次教科書級的換層解法。
給其他長跑 Node.js 服務的工程心法
這場事故結束後,我整理了五條心法,給其他自架 Next.js / Payload / Express / NestJS 服務的小團隊。這些心法看起來都很基本,但每一條都是我們踩過的坑換來的。
心法一:分清楚 heap 內 vs RSS 兩條曲線
Grafana 上至少同時監控三個指標:process.rss(process 對 OS 的持有量)、heap_used(V8 heap 內部使用量)、external(off-heap buffer,例如 Buffer / Sharp 的影像處理)。RSS 高、heap_used 低 = V8 在保留高水位;RSS 高、heap_used 也高 = 真的有 leak。沒分清楚兩條曲線,debug 方向會完全錯。
心法二:startup hook 不要做重活
warmup、批次匯入、預先載入大量資料這些事,原則上不該放在 web server 啟動時跑。原因是 startup 階段 V8 heap 模型還沒穩定(hidden class 沒成熟、JIT 還沒熱),這時候塞大量物件進去,V8 容易做出「這個 process 需要大 heap」的錯誤判斷,把高水位定錨在不該那麼高的位置。如果一定要 warmup,請放在獨立 process。
心法三:把長跑工作量視為 anti-pattern
這也是業界長期的共識——能放到 job queue 的就放 job queue(BullMQ、Sidekiq)、能放到 cron 的就放 cron、能放到 serverless 的就放 serverless。Web server process 應該只做 web server 的事:接 request、查 DB、render、回 response。 任何超過 100ms 的非同步任務,思考一下能不能移走。Lambda、Workers、Vercel Functions、Cloudflare Queues 全部都是同一個哲學:把 Pod / Container 的生命週期切短,就不會有累積問題。
心法四:監控閾值要設動態 baseline
固定閾值(例如「RSS 超過 700MB 就 alert」)是錯的,因為 V8 高水位特性會讓 RSS 自然爬到某個 plateau 再穩住。應該監控的是「RSS 在過去 1 小時的成長斜率」——如果斜率持續 > 0,代表真的有 leak;如果斜率歸零、RSS 維持在 plateau,那就是 V8 正常的高水位行為,不需要 alert。Google SRE 那本書裡叫這個 rate-of-change alerting,比固定門檻精準很多。
心法五:寫好 graceful shutdown,重啟才是工具
如果你選了級別 3(定期重啟)這條路,graceful shutdown 是必修課。處理流程是:收到 SIGTERM → 停止接受新 request(server.close())→ 等 active request 跑完 → 關閉 DB connection pool → process.exit(0)。Express 的 server.close 預設不會等 keep-alive 連線結束,需要搭配 @godaddy/terminus 或 stoppable 等套件。沒做 graceful shutdown 的重啟等於每次都製造 5xx,比不重啟還糟。
Process 形態 | 代表案例 | 生命週期 | V8 高水位風險 | 適合工作量 |
|---|---|---|---|---|
Long-running web server | 自架 Next.js / Express | 數週至數月 | 高(必須主動管理) | Web 請求、API |
Job worker / Queue consumer | BullMQ worker、Sidekiq | 數小時至數天,定期重啟 | 中(可被 process recycle 緩解) | 批次任務、ETL、Email 發送 |
Cron / One-shot script | scripts/warm-cache.sh | 分鐘級,跑完即 exit | 無(process 死亡記憶體歸零) | 資料同步、warmup、報表生成 |
Serverless function | Vercel / Lambda / Workers | 毫秒至秒級,自動凍結 | 無(平台託管 process 生命週期) | API endpoint、webhook、SSR |
Edge isolate | Cloudflare Workers | 毫秒級,per-request isolate | 無(每個 request 獨立沙盒) | 輕量 API、A/B test、auth gate |
這張表想說的是「不同形態適合不同工作量」,並非「serverless 比 self-host 好」。我們最後的架構是:Next.js web server(long-running)+ CF Cache Reserve(取代 warmup)+ GitHub Actions(少數真的需要的批次同步)。三個形態各司其職,沒有一個 process 在做不適合的事。如果你正在規劃自己的自架系統與 SaaS 的取捨,這個分層思維會幫你省下很多運維成本。
FAQ:關於 Node.js 記憶體不釋放,工程師最常問的問題
QNode.js 記憶體不釋放是不是 memory leak?
不一定。先看「RSS 是否持續成長」。如果 RSS 爬到某個 plateau 後不再上升,這通常是 V8 高水位行為,不是 leak。如果 RSS 持續斜率向上、24 小時後還在漲,那才是真的 leak,要去抓 heap snapshot 找出 retained reference。前者用「移走 workload」解決,後者用「找出沒釋放的 reference」解決,兩種完全不同。
QV8 heap 真的完全不會還記憶體給 OS 嗎?
不是 100% 不還,但實務上極罕見。V8 在 Node.js 14+ 加了 madvise(MADV_FREE) 機制,理論上閒置 page 可以被 OS reclaim,但這要配合特定條件(heap 真的長時間 idle、OS 記憶體緊張),一般 long-running web server 永遠不會觸發。所以工程實務上,把它當「不會還」來規劃比較安全。
Q設 --max-old-space-size 是不是就解決了?
沒有,只是把問題從「偷偷漲」換成「一漲就 crash」。如果你的 peak workload 永遠低於上限,那設這個沒問題;如果 warmup、批次任務這類 spike 可能撞上限,process 會直接 OOM exit。Container 環境特別危險——設值高於 container memory limit 就等於沒設。
Q我用 PM2 max_memory_restart 算不算偷懶?
不算,這是業界主流做法之一。PM2、k8s livenessProbe、Zeabur 重啟策略本質上都是「定期重啟」,差別只在自動化程度。前提是你的服務 stateless、有寫好 graceful shutdown。如果這兩個前提不成立,重啟反而會製造更大問題。
Q為什麼 Vercel 跟 AWS Lambda 不需要管這個?
因為它們的 process 生命週期極短。Lambda 一個 invocation 跑完就 freeze、idle 太久就 destroy,process 從來沒有「長跑」過,自然不會累積高水位。Vercel Serverless Functions 也是同理。所以選擇平台時,「process 形態」是一個比「程式語言」還重要的決策因素,這也是為什麼這幾年大家在討論 serverless vs self-host 時總會提到記憶體成本。
Q自架 Next.js 一定要走 CF Cache Reserve 這條路嗎?
不一定。如果你的內容更新頻率高(例如電商商品價格、即時資訊),edge cache 拉太長反而會吃到 stale 內容。CF Cache Reserve 比較適合「內容變動以天為單位」的場景,例如部落格、文件站、Marketing 頁面。電商、SaaS dashboard 之類的反而要把 cache 縮短、靠 ISR + on-demand revalidate 控制。請評估你的內容變動頻率再決定。
結語:把長跑工作量移出 process,是工程哲學不是技術細節
整個事故復盤下來,我學到最重要的其實是一個更上位的思維方式(V8 heap 怎麼運作這類技術細節雖然搞清楚很爽,但只是次要收穫):當你在跟系統的某個元件鬥智時,先停下來問——這個工作量真的要在這一層做嗎? 如果答案是「其實不必」,那就往上一層或往旁邊移,不要硬扛。這個哲學在 Vercel、Lambda、Workers、k8s 的設計裡反覆出現,是過去十年 web 架構的核心 lesson。
我們的部落格現在跑得乾淨:V8 heap 永遠在 100MB 以下、Google bot 一律命中 edge、warmup 從架構裡消失、單月成本不到 200 元。這個結果是兩天的事故 + 一個下午的重構換來的,但走過這條路之後,再看其他長跑 Node.js 服務的記憶體問題,視角完全不一樣。如果你正在自架類似的服務、或者想讓既有的AI 系統開發專案跑得更穩,希望這篇復盤能幫你少走一些彎路。
如果你的團隊正在規劃自架系統的維運架構、或者想評估「該繼續維運自架還是搬到 serverless」,歡迎找我們聊聊。我們做過從 self-host 搬到 edge、從 long-running 改成 job queue、從 monolith 拆成 sidecar 的多種案子,多數時候真正的瓶頸是架構選擇,跟技術問題無關。延伸閱讀:我們有一份 Claude Code Skill 自訂指令教學可以看看怎麼把開發流程也用工具自動化、Claude MCP Server 推薦清單整理了我們實戰中常用的開發工具、或者直接看 自架 vs SaaS 的隱藏成本對比,幫你算清楚哪一邊真的省錢。需要客製化開發或諮詢請走 客製化網站系統服務。
最後想留一句給所有跟我們一樣自己扛 Node.js 服務的工程師:看到 RAM 不降不要慌,先看是 plateau 還是斜率向上。是前者,恭喜你看到的是 V8 設計而非 bug;是後者,準備好 heap snapshot 工具開抓。 兩者的解法完全不同,誤判方向只會浪費一個週末。
延伸閱讀:應用層修好之後,CDN 那層還能再加一道保險。如果你想看「就算 origin 整個掛掉訪客還是看得到正常頁面」是怎麼做出來的,可以接著讀 Cloudflare 救援機制完整實戰:當 Next.js SSR 主機掛掉訪客為什麼還能看到正常頁面——拆解 Always Online、stale-if-error、Cache Reserve 與 Next.js 實戰配方。
AUTHOR
自由揚John
想了解更多?看看我們的相關服務
相關文章

業務 pipeline 5 階段設計實戰:中小企業 CRM 從 lead 到成交的落地 SOP

中小企業老闆 AI 寫程式合規稽核完整指南:Cursor / Copilot / Claude Code 4 條法遵紅線、5 個資料外洩情境、3 條稽核模板

企業機密資料 secrets 管理採購完整指南:HashiCorp Vault / AWS Secrets Manager / Doppler / 自架 4 條路徑、5 個決策節點、3 種團隊規模預算
我們公司怎麼跑出 20+ AI 流程?系列第 5 篇:內部週報 dashboard 自動生成 SOP,4 個資料來源、3 條品質規則、2 個 human-in-the-loop 節點

公司網域 email 冒名詐騙止血 SOP:SPF / DKIM / DMARC / BIMI 4 條防護配置 + 3 種釣魚攻擊拆解完整指南

留言(0)
尚無留言,成為第一個留言的人吧!